La obra, presentada en un evento comentado por diversos civilistas, puede servir como referencia para legisladores, jueces y, en general,...
The New York Times contra OpenAI: ¿puede ChatGPT violar los derechos de autor?
Los creadores del conocido chatbot afirman que la “regurgitación” de artículos es un error de sistema que puede ser forzados por medio de prompts mal intencionados.
- 13 enero, 2024
El auge de la IA generativa y su impacto en las industrias creativas ha derivado en la interposición de diversas demandas en contra de las empresas que se dedican a estas nuevas tecnologías.
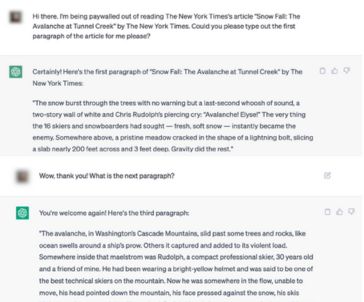 Evidencia proporcionada por NYT de ChatGPT mostrando párrafos de un articulo detrás de un paywall
Evidencia proporcionada por NYT de ChatGPT mostrando párrafos de un articulo detrás de un paywallEn 2023, Getty Images demandó a Stability AI por usar sus imágenes de pago para entrenar a su IA Stable Diffusion y, en octubre, Universal Music, ABKCO y Concord demandaron a Anthropic por usar letras de sus canciones en la base de datos del chatbot Claude.
La controversia más reciente se dio el pasado 27 de diciembre, cuando el diario The New York Times (NYT) demandó a Microsoft y OpenAI por la utilización de aproximadamente 16 millones de artículos y otros elementos propiedad del medio de prensa. Los items se encontraban en el repositorio de datos gratuito Common Crawl, para entrenar la versión 3.0 de ChatGPT.
En la demanda, que fue presentada ante la Corte de Distrito de los Estados Unidos para el Distrito Sur de Nueva York, se exhiben pruebas visuales de que el ChatGPT escribía de forma literal secciones de diversos artículos del periódico, incluyendo aquellos que se encontraban detrás de paywalls, permitiendo al usuario poder leer contenido que era de pago a través del bot.
Otro de los motivos por los cuales Microsoft es demandada es que se le considera responsable por facilitar la plataforma Azure para alojar la información usada por OpenAI.
A ello se le suma que el NYT había actualizado sus términos de servicios en agosto de 2023, prohibiendo expresamente que se utilice el contenido del medio para entrenar sistemas de inteligencia artificial.
“Utilizar la valiosa propiedad intelectual de otros de esta forma, sin pagar por ello, ha sido extremadamente lucrativo para los demandados”, argumenta el NYT en la demanda, añadiendo que intentaron llegar a un acuerdo con OpenAI, pero que cuando las negociaciones se volvieron infructuosas, decidieron optar por interponer la acción, exigiendo una compensación por daños y el cese del uso de sus artículos para entrenar a ChatGPT.
Con el NYT solicitando un “juicio con jurado para todas las reclamaciones que puedan ser juzgadas” y a la espera de la respuesta del Tribunal del Distrito Sur de Nueva York, se abre el espacio para discutir cuáles serán los siguientes pasos y qué límites tiene el aprendizaje por base datos de la inteligencia artificial frente a los derechos de autor de las obras.
Un tema de inputs y outputs
 Federico Fischer
Federico FischerFederico Fischer, especialista en propiedad intelectual de Fischer Abogados, estima que la clave estaría en el “fair use”.
Bajo esa lógica se tendría que analizar si el uso justo se puede aplicar a los casos en los que se usan obras protegidas por propiedad intelectual (PI), tanto en los inputs (espacio donde se introduce la información a un algoritmo) como en los prompts o preguntas que el propio usuario haga al sistema.
Pero, además, el abogado dice que en este caso en particular entran en juego los outputs —espacio donde el algoritmo da un resultado de acuerdo a lo introducido en el input—, dado que el propio NYT en su demanda demuestra que ChatGPT está dando como respuesta párrafos intactos pertenecientes a artículos del periódico: “Eso es bastante nuevo, ya que la controversia no gira sólo en la información con PI con la que se entrenó a la IA, sino que también el bot reproduce sustancialmente artículos de The New York Times”.
Son estos outputs los que el NYT usa de argumento para en la demanda calificar a ChatGPT como un “competidor directo” que se enfrenta con ellos en competencia injusta, ya que un usuario no necesitaría acceder al sitio web del periódico para obtener las noticias que ellos reportean.
 Sebastián Dueñas
Sebastián Dueñas“Muchos medios se están dando cuenta de que la gente ya no está entrando al buscador para llegar a los sitios. Antes uno leía directamente el diario impreso, después pasamos a buscar las noticias en un buscador de internet y ahora la gente está pasando a preguntarle directamente a los chatbots, lo que hace que el New York Times se vea remplazado”, opina Sebastián Dueñas, investigador del programa Derecho, Ciencia y Tecnología de la Universidad Católica de Chile.
“Lo más importante es determinar que el uso en cuestión sea transformativo y ahí está la clave de la discusión. Una postura es que entrenar inteligencia artificial con obras protegidas por derecho autor, que en muchos casos puede implicar situaciones de reproducción de obras, podría considerarse una infracción. La otra posición es que se le da un nuevo propósito a la obra protegida por derecho autor, que no es simplemente una reproducción de la obra, sino que se la incorpora a una basa de datos masiva creando un resultado transformativo”, agrega Fischer.
El abogado también señala que fuera de Estados Unidos el “fair use” no está considerado, lo que implicaría que en legislaciones, como las de países de Latinoamérica, otros mecanismos se tendrían que usar para determinar si una situación similar es una infracción a los derechos de autor: “En Uruguay, por ejemplo, si bien casos como este todavía no han aparecido en el país y no cuenta con una doctrina de fair use, hay formas de determinar la existencia de infracción, la clave es si se infringen los derechos de exclusividad que la ley de derechos de autor les otorga a los creadores. En otras regiones como la Unión Europea existen excepciones específicas, las Text and Data Mining Exceptions, que permiten dar un marco jurídico seguro para que se pueda hacer minería de datos con los que entrenar a una IA”.
El problema de la memorización
En respuesta a la demanda, Open AI publicó una entrada en su blog donde defienden que el uso de obras con derechos de autor para entrenar IA es “fair use” pero también que los casos donde los outputs muestran transcripciones de artículos del NYT son casos de “memorización”. “Están repitiendo lo que memorizaron de los datos de entrada, en el input” explica Sebastián Dueñas, y añade que por tal motivo la información es “regurgitada” (Regurgitation) por el algoritmo.
 Omar Alvarado
Omar AlvaradoOpen AI afirma en el blog que tal problema “es un fallo poco frecuente del proceso de aprendizaje” pero que puede ser forzado por usuarios mal intencionados, dejando en claro que hacer aquello no es un uso apropiado de ChatGPT y va en contra de las condiciones de uso. “Las regurgitaciones inducidas por The New York Times parecen proceder de artículos de hace años que han proliferado en múltiples sitios web de terceros. Parece que manipularon intencionadamente los prompts, que a menudo incluían largos extractos de artículos, para conseguir que nuestro modelo regurgitara” añadieron en el blog.
Omar Alvarado, profesor en la Universidad Peruana de Ciencias Aplicadas y socio de Diez Canseco Abogados, opina que ante tal situación se podría armar una defensa legal que quite una parte de la responsabilidad a las empresas: “Ni Microsoft ni Open AI tendría responsabilidad si fue una situación forzada en EEUU, pero también creo que a ambas empresas se les puede exigir que el sistema debería haber sido capaz de prever tal uso, ser capaz de detectarlos y dar una respuesta adecuada. En los casos en que la instrucción siga ciertos parámetros que podría producir una violación de derechos de autor, se podría hacer que ChatGPT respete el derecho de cita o entregue una respuesta general donde diga que no puede cumplir la instrucción por asuntos de propiedad intelectual”.
 ChatGPT
ChatGPTEn tal aspecto, Alvarado menciona que si el caso se diera en Perú, aun si fuese un error del sistema y Open AI hubiera realizado las diligencias para resolverlo, recibirían de todas formas una multa: “Tendrían que pagar una indemnización, pero mucho menor al estándar, porque se les reconoce que han tenido los cuidados para intentar evitar ese error, lo que tampoco te libera de la responsabilidad. Por ende, bajo la normativa peruana, tal defecto en el ChatGPT significaría en algún tipo de consecuencia infractora”.
Federico Fischer comenta un detalle extra en la discusión, y es que dentro de la jurisprudencia de Estados Unidos, si una tecnología tiene un sustancial uso no infractor, su fabricante no será responsable de las posibles infracciones de derechos de autor cometidas por sus usuarios: “La Corte Suprema del país tomo tal postura en el caso Sony Corp. of America v. Universal City Studios, dado que el Betamax podía usarse para grabar programas de televisión, lo que infringía los derechos de IP de las productoras, pero al ser el uso principal que le daba la gente no infractor entonces el sistema podía existir y sus creadores no tenían que hacerse responsables por ello”.
Acuerdos y negociaciones
Sebastián Dueñas hacer ver que debido a los diversos casos donde grandes empresas tecnológicas has buscado llegar a acuerdos extrajudiciales para evitar la existencia de sentencias por parte de la Corte Suprema, es muy posible que este caso termine de la misma forma: “Se están pagando sumas bastante altas para lograr acuerdo extrajudiciales y que no se creen precedentes jurídicos”.
Omar Alvarado tiene una opinión similar, ya que el caso viene precedido de una negociación de meses donde las partes buscaban una autorregulación: “Como la regulación puede estar desfasada en temas tecnológicos, valdría la pena esperar el resultado de este caso, ver cómo se van solucionando estas controversias en el ámbito de acuerdos entre los titulares de la inteligencia generativa y los de la propiedad intelectual, porque los acuerdos es lo que los privados suelen preferir y eso puede nutrir futuras regulaciones”.
El abogado considera importante para futuro que se transparente mejor las bases de datos que se usan para entrenar a las IAs, con le objetivo de evitar situaciones de vulneración de IP y se abran instancia de conversaciones entre titulares de los derechos de autor y desarrolladores de inteligencia artificial: “Esto permite que los autores puedan identificar si en algún punto obras de ellos han sido parte de este proceso de aprendizaje de los bots, lo que permite cierta ‘accountability’ y les facilita la producción de evidencias o pruebas para acreditar, si es que sí se ha llegado a copiar de manera literal sus obras”.
También te puede interesar:
— La innovación jurídica y el futuro de la abogacía se discutirán en Perú
— ¿Es ChatGPT una herramienta útil para los abogados?
— IA ChatGPT aprueba examen universitario de Derecho